Theano 入門¶
本文書ではPython用の数値計算ライブラリTheanoの使い方を説明します. 応用例としてRestricted Boltzmann Machineを実装します.
Contents
はじめに¶
Theano はPython用の数値計算ライブラリです. PythonではNumpyが数値計算ライブラリの事実上の標準となっていますが, TheanoではNumpyのように計算手続きを記述するのではなく, 数式そのものを記述します. このことによって, 計算対象となる行列等の実体のプログラム内での引き回しを考える事なく, 最適化やGPUによる高速化の恩恵が受けられます. また, Theanoでは数式そのものを記述するので, 微分を (数値的ではなく) 解析的に実行する事が出来ます. TheanoはLinux, Mac OSX, Windows上で動作します.
Theanoはモントリオール大学のBengio教授の研究室で開発されています. この研究室はdeep learningと呼ばれる機械学習手法を研究しており, Theanoはdeep learningへの応用を強く意識して設計されています. 例えば, Deep learningの手法が数多く実装されている Pylearn2 というライブラリはTheanoがベースになっています.
公式サイトにTheanoを用いたdeep learningの実装方法を説明した素晴らしい ドキュメント があります. このドキュメントは分かりやすく書かれているのですが, かなり分量が多く, ある程度複雑な応用 (一番最初に説明されている応用例は logistic regression です) にたどり着くまでの敷居が高いように思えます. そこで, 本文書では説明を必要最低限に留めて, Theanoによる数値計算の応用を概観することを目的としました.
本文書では, Theanoの応用例としてrestricted Boltzmann machine (RBM) を取り上げます. RBMを実装し, MNIST手書き文字データセットに対して適用することで特徴量抽出を行います. 元々のRBMは二値を取るユニットで構成されました. これをここではbinary-binary型RBM (BBRBM; 通常は単にRBMと呼ばれます) と呼びます. BBRBMは基本的には二値データの処理に適しています. 連続値を取るデータに対しては, 観測データを確率値とみなして処理します. 別の方法として, RBMの連続値への拡張があります. その中で代表的なものは, ユニットの条件付き分布としてガウス分布を持つGaussian-binary型のRBM (ここではGBRBMと呼ぶこととします) です. 本文書では, 二値のRBM (Binary-binary RBM, BBRBM) とGBRBMの二種類のRBMを実装します.
本文書は次のように構成されます. まずTheanoを用いた基本的な計算方法, メモリを使いまわすための共有変数, 数式の微分, 乱数の生成の基本について説明します. 次にRBMについて簡単に説明します. そしてTheanoを用いたRBMの実装について述べ, 最後にプログラムの実装結果を示します.
本文書では, 読者はPythonとNumpyについて既知であると仮定しました. しかしこれらの知識が無くても, CやJavaを日常的に使っていれば, 本文書のコードは読めると思います. また, 産総研の神嶌先生が執筆されたNumpyの素晴らしいチュートリアル 機械学習のPythonとの出会い を読まれると良いと思います. 言語仕様ではなく, どのようにNumpyを数値計算に使うかがよく分かります.
実行環境¶
プログラムの動作確認はWindows7とMac OSXで行いました. Pythonの環境構築には Anaconda を使用しました. Anacondaのインストール後, Githubに置かれている最新版のソースコードを用いてTheanoをインストールしました (インストール方法は こちら を参照してください).
Mac OSX上ではGPUによる動作も確認しました. CUDAのバージョンは5.5です. GPUを用いることをTheanoに教えるため, 次のような.theanorcファイルをホームディレクトリに置きました:
[cuda]
root = /Developer/NVIDIA/CUDA-5.5
[global]
device = gpu
#device = cpu
floatX = float32
force_device = True
allow_gc = False
[nvcc]
fastmath = True
[gcc]
cxxflags = -O3 -ffast-math -funroll-loops -ftracer
動作確認用のデータとして, Theanoの公式サイトにあるmnist.pkl.gzを使用しました. こちら のTheanoチュートリアルサイトからダウンロードできます.
ソースコード¶
ソースコードは以下の三つです:
- bbrbm.py : BBRBMクラスを含むファイルです.
- gbrbm.py : GBRBMクラスを含むファイルです.
- test_rbms.py : テスト用関数を含むファイルです.
Theanoを用いたRBMの実装に関連するのは上の二つです.
Theano関数の生成¶
以下の説明では, iPythonコンソール上での実行結果を示します. 次のように入力し, Numpyモジュールをロードします:
>>> import numpy as np
シンボルの生成と式の定義¶
Theanoはスカラー, ベクトル, 行列, テンソルを表す変数をシンボルとして扱います. シンボルの生成はtheano.tensorモジュールの関数を用いて行います:
>>> import theano.tensor as T
>>> x = T.dscalar('x')
二行目でfloat型のスカラーを表すシンボルxを宣言しています. 先頭の’d’はdoubleを表します. 括弧の中の文字列はシンボルの名前を表します. これは省略可能です. 名前を与えておくとエラーメッセージの表示で用いられます. ここではスカラー変数を生成しましたが, dvector(), dmatrix(), dtensor3()などの関数を用いてベクトル, 行列, テンソルも同様に生成することができます. 詳しくは このページ を参照して下さい.
生成したシンボルを用いて, 次のようにして数式を定義します:
>>> y = x**2
>>> z = x**2 + y
それぞれ  ,
,  (すなわち
(すなわち  ) を表します.
) を表します.
関数の生成¶
シンボルを用いて定義した数式はそのままでは計算できません. 数式が表す計算に対応する関数を生成する必要があります. 関数の生成はtheano.function()を用いて行います:
>>> from theano import function
>>> f = function(inputs=[x], outputs=z)
theano.function()を呼び出すと数式で表される計算プログラムがコンパイルされます. 引数inputとoutputはそれぞれ生成される関数の入出力に対応するTheanoのシンボルです. 入力はリストとする必要があります.
上の例では, 生成されるTheano関数は変数fに代入されます. これを便宜上関数fと呼びます. 関数fの引数と戻り値はNumpy配列です. inputs=[x]は関数fの入力であるNumpy配列を, Theanoが管理する, シンボルxに対応するメモリ領域にコピーすることを表します. 逆に, outputs=zはシンボルzが表す値を, 関数fの戻り値であるNumpy配列にコピーする事を表します. このようなNumpyとTheano間のメモリコピーによって, PythonのプログラムからTheanoのシンボルで構築した数式の計算を実行できます.
動作を確認します:
>>> f(3)
array(18.0)
ベクトルはNumpy配列として与えます. スカラーの場合と同様に動作を確認します:
>>> x = T.dvector('x')
>>> y = x**2
>>> z = x**2 + y
>>> f = function(inputs=[x], outputs=z)
>>> a = np.array([1., 2., 3.])
>>> f(a)
array([ 2., 8., 18.])
ベクトルのサイズは関数の入力に与えられたNumpy配列のサイズから決まります. Theanoの式の中で配列サイズを取得するにはshape属性を使用します:
>>> x = T.dmatrix('x')
>>> s0 = x.shape[0]
>>> s1 = x.shape[1]
>>> f = function(inputs=[x], outputs=[s0, s1, s0 * s1])
>>> a = np.zeros((4, 3))
>>> f(a)
[array(4), array(3), array(12)]
この例では複数の出力を取る関数を生成しています.
Theanoは要素毎の加減乗除, 内積, 外積などの基本的な演算や, 最大値, 最小値, 指数関数, 対数関数, 逆行列計算といった様々な関数をサポートします. 詳しくは このページ を参照して下さい.
微分¶
微分の計算¶
微分の計算はtheano.tensor.grad()を用いて行います:
>>> x = T.dvector('x')
>>> y = x**2
>>> z = T.sum(x**2 + y)
>>> gz = T.grad(cost=z, wrt=x)
>>> f = function(inputs=[x], outputs=gz)
grad()の引数costは微分の対象となる関数, 引数wrtは微分を取る変数です.
結果を確認します:
>>> a = array([ 1., 2., 3.])
>>> f1(a)
array([ 4., 8., 12.])
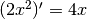 に
に 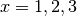 を代入した値と一致します.
を代入した値と一致します.
定数の指定¶
上述した数式では  は
は  の関数であるため, の関数である
の関数であるため, の関数である  を で微分すると が表す関数も微分の対象となります. しかし, を に依存しない定数として扱いたい場合があります. 上記の式で を定数として扱うには次のように引数consider_constantsを用います:
を で微分すると が表す関数も微分の対象となります. しかし, を に依存しない定数として扱いたい場合があります. 上記の式で を定数として扱うには次のように引数consider_constantsを用います:
>>> x = T.dvector('x')
>>> y = x**2
>>> z = T.sum(x**2 + y)
>>> gz = T.grad(cost=z, wrt=x, consider_constant=[y])
>>> f = function(inputs=[x], outputs=gz)
結果を確認します:
>>> a = array([ 1., 2., 3.])
>>> f(a)
array([ 2., 4., 6.])
共有変数¶
共有変数の生成¶
Theanoを用いて生成した関数を使用する際, 入出力であるNumpy配列のメモリコピーによるオーバーヘッドが発生します. 共有変数はTheanoの内部でメモリを使い回すための仕組みを提供します. 共有変数は確率モデルのパラメータを保持するのに用いることができます. 勾配法に基づくパラメータ推定法ではパラメータの値が何度も更新されますが, その場合, 共有変数を用いると無駄なメモリコピーが不要となります. また, パラメータ推定に用いる学習データを共有変数として与えておくと, パラメータ更新の度に学習データのTheanoメモリ空間へコピーする必要がなくなります.
共有変数の生成はtheano.shared()を用いて行います:
>>> from theano import shared
>>> m = shared(np.zeros((3, 3)), name='m')
>>> n = shared(np.array([1.5, 2.5, 3.5]), name='n')
変数mとnはTheanoのシンボルであり, その中身はTheanoの数式の内部からしか参照する事ができません. 共有変数の中身をNumpy配列にコピーするためにはメソッドget_value()を使用します:
>>> m.get_value()
array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> n.get_value()
array([ 1.5, 2.5, 3.5])
共有変数の参照¶
共有変数はTheanoの数式から参照できます:
>>> x = n * 3
>>> f = function(inputs=[], outputs=x)
>>> f()
array([ 4.5, 7.5, 10.5])
上記の関数f()の呼び出し後もnの値がそのままであることを確認します:
>>> n.get_value()
array([ 1.5, 2.5, 3.5])
インデックスによる参照¶
共有変数をインデックスで参照する事も可能です. 以下はその例です:
>>> ixs = T.lvector()
>>> x = y * 3
>>> f = function(inputs=[ixs], outputs=x, givens={y: n[ixs]})
>>> ixs_ = np.array([0, 2]).astype(int)
>>> f(ixs_)
array([ 4.5, 10.5])
1行目では配列インデックスに対応するlong型整数ベクトルを表すシンボルixsを生成しています. 3行目では引数givensが与えられています. この引数は辞書で, 関数の実行前に, キーのシンボルが表す変数にバリューの値を割り当てる事を意味します. この方法は, 同じ値を同じ関数に何度も適用する場合に有効です (要確認) .
共有変数の更新¶
次のコードは共有変数を更新する例です:
>>> n = shared(np.array([1.5, 2.5, 3.5]), name='n')
>>> f = function(inputs=[], outputs=[], updates={n: n * 2})
>>> n.get_value()
array([ 1.5, 2.5, 3.5])
>>> f()
[]
>>> n.get_value()
array([ 3., 5., 7.])
>>> f()
[]
>>> n.get_value()
array([ 6., 10., 14.])
2行目でfunction()にupdatesという引数を与えています. この引数は辞書であり, ここで生成された関数 (変数fに代入されます) が実行されるときに, キーの共有変数がバリューの値に置き換えられることを意味します. 共有変数と置き換わる式の組の集合は, タプルのリストとして与える事も出来ます. RBMの例では, モデルパラメータの更新量を計算しておき, 引数updatesを用いてパラメータを更新する, ということを行います.
乱数の使用¶
Theanoでは, 確率変数を表す式によって乱数を使用する事が出来ます. 確率変数を表す式の生成にはRandomStreamsオブジェクトを使用します. 次はその例です:
>>> from theano.tensor.shared_randomstreams import RandomStreams
>>> rng = RandomStreams(1234)
>>> x = rng.normal((10,))
>>> y = rng.binomial((10,), p=0.5, n=1)
>>> z = x * y
>>> f = function(inputs=[], outputs=[x, y, z])
>>> f()
[array([ 0.74027121, -0.39038867, 2.02702785, -0.46713907, 0.76772332,
-1.06572402, 0.46626514, -0.57883042, -1.94698334, -0.43333766], dtype=float32),
array([0, 0, 1, 0, 0, 1, 1, 1, 1, 0], dtype=int64),
array([ 0. , -0. , 2.02702785, -0. , 0. ,
-1.06572402, 0.46626514, -0.57883042, -1.94698334, -0. ])]
>>> f()
[array([ 1.50351787, 0.08276177, -0.22685656, 0.43249258, -0.27572322,
-0.15955459, -0.50829798, 0.72116745, 1.15433073, 1.41766679], dtype=float32),
array([1, 0, 1, 1, 1, 0, 0, 0, 0, 0], dtype=int64),
array([ 1.50351787, 0. , -0.22685656, 0.43249258, -0.27572322,
-0. , -0. , 0. , 0. , 0. ])]
xとyはそれぞれ正規分布および二項分布に従う確率変数を要素とする長さ10のベクトルで, zはそれらの積です.
Restricted Boltzmann Machine (RBM) の説明¶
これまでに説明したTheanoの機能を用いる事でRBMを実装する事が出来ます. まず初めに二種類のRBM (Binary-binary型, Gaussian-binary型) について簡単に説明します.
RBMの確率分布¶
RBMは 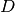 次元観測変数
次元観測変数 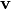 と
と  次元隠れ変数
次元隠れ変数 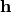 の同時分布
の同時分布  を表します. RBMの確率分布はエネルギー関数
を表します. RBMの確率分布はエネルギー関数 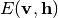 を用いて次のように表されます [3] :
を用いて次のように表されます [3] :
(1)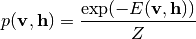
ここで  は正規化項です:
は正規化項です: 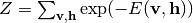 . 和の記号は変数が取り得る値を渡ります. 変数が連続値を取る場合は積分記号に読み替えます. この分布はエネルギーが低い状態の出現確率が高いことを表します. 式 (1) の形の確率分布を持つモデルはenergy-based model (EBM) と呼ばれます. Boltzmann machineやRBMもenergy-based modelです. RBMは同じ層の変数間が結合をもたないBoltzmann machineです.
. 和の記号は変数が取り得る値を渡ります. 変数が連続値を取る場合は積分記号に読み替えます. この分布はエネルギーが低い状態の出現確率が高いことを表します. 式 (1) の形の確率分布を持つモデルはenergy-based model (EBM) と呼ばれます. Boltzmann machineやRBMもenergy-based modelです. RBMは同じ層の変数間が結合をもたないBoltzmann machineです.
観測変数, 隠れ変数が共に二値を取るBinary-binary型のRBM (通常単にRBMと呼ぶ場合, この型のものを指します) の場合, エネルギー関数の形は次のようになります:
(2)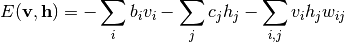
ここで 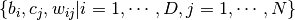 はRBMのモデルパラメータを表します. と の条件付き分布は次のようになります:
はRBMのモデルパラメータを表します. と の条件付き分布は次のようになります:
(3)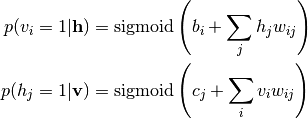
つまり変数は全て条件付き独立です. この条件付き独立性のため, Gibbsサンプリングを容易に行う事ができます. GibbsサンプリングはRBMのパラメータ推定に用いられます (後述) .
観測変数が連続値, 隠れ変数がニ値を取るGaussian-binary型のRBM (GBRBM) の場合, エネルギー関数の形は次のようになります:
(4)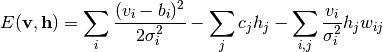
ここで 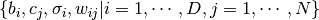 はRBMのモデルパラメータを表します. と の条件付き分布は次のようになります:
はRBMのモデルパラメータを表します. と の条件付き分布は次のようになります:
(5)
Energy-based modelの勾配計算¶
観測変数に対する対数尤度  を勾配法で最大化することで最尤推定を行う事を考えます. RBMに限らず, 式 (1) の形を持つEBMのパラメータに関する勾配は以下のようにして計算できます.
を勾配法で最大化することで最尤推定を行う事を考えます. RBMに限らず, 式 (1) の形を持つEBMのパラメータに関する勾配は以下のようにして計算できます.
エネルギー関数のパラメータを 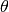 で表します. 観測データ
で表します. 観測データ 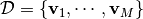 に対する対数尤度を次式で定義する:
に対する対数尤度を次式で定義する:
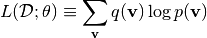
ここで 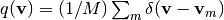 はデータの経験分布を表します. 観測データ に対する対数尤度は次のように変形できます:
はデータの経験分布を表します. 観測データ に対する対数尤度は次のように変形できます:

右辺第一項のパラメータ微分は次のようになります:
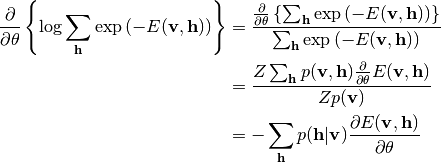
第二項のパラメータ微分は次のようになります:
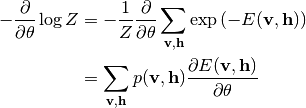
したがって, 対数尤度のパラメータ微分は次のようになります:
(6)
ここで  は隠れ変数の分布をEBMの条件付き分布としたときのデータ分布に関する期待値,
は隠れ変数の分布をEBMの条件付き分布としたときのデータ分布に関する期待値, 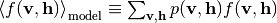 はEBMのモデル分布に関する期待値をそれぞれ表します.
はEBMのモデル分布に関する期待値をそれぞれ表します.
式 (6) に (2) および (4) を代入するとRBMのパラメータ微分が得られます. 例えば, GBRBMの重みパラメータ  に関する対数尤度の微分は次式のようになります:
に関する対数尤度の微分は次式のようになります:

他のパラメータに関する微分も同様に計算されます. Theanoによる実装ではこの式は使用せず, 代わりに上述したように関数grad()を用います. そのとき, 式 (6) の形に注目して, 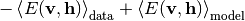 を仮のコスト関数としてその微分を計算します.
を仮のコスト関数としてその微分を計算します.
Contrastive divergence (CD) algorithm¶
式 (6) を用いて勾配法を適用しパラメータを推定する事ができます. しかし, この式の第二項は変数の組み合わせ爆発のため解析的に計算する事は困難です. また, モンテカルロ法を使って二項目を評価する事ができますが, 充分な精度を得るのに必要なサンプリング回数はかなり多いと予想されます.
上記の問題を解決する方法として, トロント大学のHinton教授はcontrastive divergence (CD) アルゴリズムを提案しました [4] . CDアルゴリズムでは, 学習データから始まるマルコフ連鎖モンテカルロ法 (MCMC) を少ない回数 (典型的には1回) 実行し, そのサンプリングを用いて第二項の期待値を計算します. この方法は尤度ではなくcontrastive divergenceという量を最小化するアルゴリズムとみなすことができます [4] . CDアルゴリズムによって得られるパラメータは一般に最尤パラメータとは異なりますが ([2], [1] ), その違いは小さい事が経験的に確かめられています. また, CDアルゴリズムではパラメータ更新の度に学習データから始まるMCMCを実行するのですが, persistent CD (PCD) アルゴリズムと呼ばれる手法では, サンプルを記録しておいて学習の最中マルコフ連鎖を継続させます [5] . この方法では, マルコフ連鎖の収束 (混合) と比べてパラメータの変化が緩やかなら, 原理的には最尤パラメータが得られます.
RBMの実装¶
ここではRBMの実装について説明します. 実装の方針について一点注意があります: クラスから呼び出される関数で状態を持たない(selfへの参照を必要としない)ものは, 静的メソッドではなく, クラスを定義するモジュール内の関数として定義します. これは単に私の好みです. モジュール外から参照されないことを示すため, 関数名の先頭文字をアンダースコアとします.
インターフェース¶
インターフェースはPythonの代表的な機械学習ライブラリである scikit-learn に習って定義します. クラス名はBBRBM/GBRBMとし, コンストラクタでパラメータを与えます. CDアルゴリズムによるパラメータ推定はメソッドfit()で行い, 与えられた観測データに対する隠れ変数の条件付き分布をメソッドtransform(), 観測データの復元をメソッドreconstract()で行います. 後者の二つのメソッドはそれほど時間がかからないためTheanoではなくNumpyで実装します.
尤度の計算が困難であるため, RBMの学習のモニタリングには工夫が必要です. 可視変数と観測変数の両方がニ値変数であれば疑似尤度を比較的容易に計算できますが, ここでは実装の容易さのため, 学習データとテストデータの復元誤差を採用します.
BBRBMとGBRBMのメソッドfit()のコードは共通で, 以下の通りです:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | def fit(self, xs, xs_=None):
"""
xs : numpy array n_tr x D, training data
xs_: numpy array n_te x D, test data
"""
# Aliases
params_tr = self.params_tr
params_model = self.params_model
batch_size = self.params_tr.batch_size
n_samples = xs.shape[0]
d_vis = xs.shape[1]
t_start = self.t_start
t_end = self.t_end
# Initialization
params_np, hist = _init_params_all(d_vis, params_tr, params_model)
ixss, bsize = _get_minibatches(batch_size, n_samples)
# Create Theano objects
funcs_th, params_th, _ = _init_theano(xs, xs_, params_np, params_tr)
# Training loop
if params_tr.algorithm == 'cd':
hist = _cd_learning(
hist, funcs_th, params_th, params_tr, t_start, t_end, ixss)
elif params_tr.algorithm == 'pcd':
_init_particles(funcs_th, n_samples, params_tr)
hist = _pcd_learning(
hist, funcs_th, params_th, params_tr, t_start, t_end, ixss)
else:
raise ValueError(
'Invalid string of algorithm: ' + params_tr.algorithm)
# Copy theano objects to numpy array
self.params_np = _copy_params(params_th)
# Keep history of training
self.hist = hist
# Model parameter set
self.params_model = self.params_np
self.params_model.update({'hist': hist})
return self
|
このメソッドの一番目の引数xsは学習データ, 二番目の引数はテストデータです. テストデータに対する復元誤差によって過学習が起こっているかどうかを確認できます.
このメソッドで最も重要なのはL20の関数_init_theano()の呼び出しです. この関数は学習データ, テストデータ, 初期化済みのモデルパラメータ (params_np), 隠れユニット数や学習係数などのメタパラメータ (params_tr) を引数にとり, Theanoのオブジェクトを返します. より具体的には, funcs_thはTheano関数の辞書, params_thはモデルパラメータを含むTheano共有変数の辞書です. 前者はパラメータ推定のために呼び出され, 後者は推定後のパラメータをNumpy配列として保持するために用いられます.
上記のTheanoオブジェクトはすぐ後に続く学習ループで用いられます (L23-30) . パラメータparams_tr.algorithmの値によってCDアルゴリズムかPCDアルゴリズムのいずれかが適用されます.
学習ループ¶
関数_cd_learning()と_pcd_learning()はほぼ同じ構造を持ちます. ここでは前者について見ていきます. これらの関数も, BBRBMとGBRBMで共通です. コードは以下の通りです:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | def _cd_learning(
hist, funcs_th, params_th, params_tr, t_start, t_end, ixss):
if params_tr.verbose:
print('CD-1 learning loop: %d steps' % (t_end - t_start))
begin = time.clock()
for t in xrange(t_start, t_end):
# Minibatch learning
for ixs in ixss:
funcs_th['update_diffs'](t, ixs)
funcs_th['update_params']()
# Log
if params_tr.verbose and np.mod((t + 1), params_tr.n_mod) == 0:
end = time.clock()
log = _show_info(funcs_th['get_info'], t, end - begin)
begin = time.clock()
hist += [log]
return hist
|
辞書funcs_thに含まれる関数update_diffs()とupdate_params()が繰り返し呼び出されます. 外側のループが学習回数, 内側のループがミニバッチに対応します. ixsは学習データのインデックス集合(Numpy配列)で, ixssはixsのリストです.
ミニバッチは学習データの断片 (通常数十~百数十程度) を指します. 真のコスト関数は全学習データに対して定義されますが, 適当なサイズに分割されたミニバッチを用いて勾配計算とパラメータ更新を適用することで計算時間が短縮されます.
Theano関数の生成の準備¶
関数_init_theano()もBBRBMとGBRBMで同じです. コードは以下の通りです:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | def _init_theano(xs_tr_np, xs_vl_np, params_np, params_tr):
# Alias
algorithm = params_tr.algorithm
n_rate = params_tr.n_rate
# Theano shared variables, symbols and random number generator
xs_tr, xs_vl = _get_shared_vars(xs_tr_np, xs_vl_np)
params = _get_shared_params(params_np)
diffs = _get_shared_diffs(params_np)
particles = _get_shared_particles(params_tr)
v0s, ixs, t = _get_symbols()
rng = RandomStreams(seed=params_tr.seed)
# Sampling for positive and negative phase
poss = _get_poss(rng, v0s, params, n_rate)
negs = _get_negs(rng, poss, params, n_rate)
# Cost functions (energy + penalty term, see _get_cost)
cost, consts = _get_cost(poss, negs, params, params_tr)
# Updates of model parameters
us_diff = _get_updates_diff(t, cost, diffs, params, params_tr, consts)
us_param = _get_updates_param(diffs, params, params_tr)
# Concatenation of updates
if algorithm == 'pcd':
us_particles = _get_updates_particles(particles, negs)
us_diff = us_diff + us_particles
us = us_diff
# Reconstruction error
recon_err_tr = _get_recon_err(xs_tr, params, n_rate)
recon_err_vl = _get_recon_err(xs_vl, params, n_rate)
# Information for monitoring learning progress
info = _get_info(params)
# Initialization of persistent chain
us_init_particles = _get_updates_init_particles(
rng, particles, v0s, params, params_tr)
# Theano functions
return _get_theano_functions(
params, diffs, particles, algorithm, us, us_param, us_init_particles,
t, ixs, v0s, xs_tr, recon_err_tr, recon_err_vl, info)
|
L8-13でTheanoの関数を作成するために用いられるシンボル, および共有変数を作成しています. L15, 16ではGibbsサンプリングの式, L19ではコスト関数の式が生成されます. L22-28はパラメータ更新に対応する共有変数更新式が生成されます. L34, 33-34は学習・テストデータに対する復元誤差の式, L37では学習中のパラメータなどの情報を表す式 (モデルパラメータの平均値など) が生成されます. 最後に, PCDアルゴリズムのためにサンプルを保持する共有変数更新式が生成されます.
最後の行で, 以上で挙げたTheanoオブジェクト (シンボル, 式, 共有変数更新式) を, 複数のTheano関数を生成する関数_get_theano_functions()に渡しています.
Gibbsサンプリング¶
関数_get_poss()と_get_negs()はGibbsサンプリングを1ステップ実行することでRBMの観測変数と隠れ変数のサンプルを取得します. CDアルゴリズムではGibbsサンプリング連鎖の初期値を学習データ (観測変数) とします. これは_get_poss()で行われます. 一方, _get_negs()では辞書particleに含まれる隠れ変数を表す共有変数particles[‘hs’]を初期値としてGibbsサンプリングを1ステップ実行します. この関数はBBRBMとGBRBMで異なります.
GibbsサンプリングがどのようにTheanoで実装されているかを確認するため, gbrbm._get_negs()のコードを示します.
1 2 3 4 5 6 7 8 9 10 11 12 13 | def _get_negs(rng, particles, params, n_rate):
w, z, b, c = _get_params(params)
_hs = particles['hs']
def _gibbs_hvh(hs0):
vs1 = _sample_vs_given_hs(rng, hs0, w, z, b)
hs1 = _sample_hs_given_vs(rng, vs1, w, z, c, n_rate)
return [vs1, hs1]
vs, hs = _gibbs_hvh(_hs)
return {'vs': vs, 'hs': hs}
|
L5-7で条件付き分布 (5) に基づいてサンプリングを実行する式が生成されます. 関数_sample_vs_given_hs()は, 隠れ変数所与の下での観測変数の条件付き分布 (ガウス分布) からサンプリングを行う式を生成します. もう一つの関数_sample_vs_given_hs()は観測変数所与の下での隠れ変数のサンプリング (ベルヌーイ分布) に対応します. サンプリング結果は辞書に格納されて呼び出し側に返されます.
関数_sample_vs_given_hs()と, その中から呼び出される関数_meanstd_vs_given_hs()のコードを続けて示します:
1 2 3 4 | def _sample_vs_given_hs(rng, hs, w, z, b):
ms, ss = _meanstd_vs_given_hs(hs, w, z, b)
vs = rng.normal(size=ms.shape, avg=ms, std=ss, dtype=cnf.floatX)
return vs
|
1 2 3 4 | def _meanstd_vs_given_hs(hs, w, z, b):
s = T.exp(z)
m = T.dot(hs, w.T) + b
return m, T.sqrt(s)
|
前者がガウス分布によるサンプリング, 後者が条件付き分布の平均と標準偏差の計算にそれぞれ対応します. 条件付き分布の式がほぼそのまま実装されていることが分かると思います. 以上の関数は, ガウス分布をベルヌーイ分布に置き換えて, BBRBMでも同様に実装されます.
コスト関数の計算¶
コスト関数の式を返す_get_cost()と, その中から呼び出される関数_energy()のコードはBBRBMとGBRBMで異なります. GBRBMのコードは以下の通りです:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | def _get_cost(poss, negs, params, params_tr):
vs_pos, hs_pos = poss['vs'], poss['hs']
vs_neg, hs_neg = negs['vs'], negs['hs']
w, z, b, c = _get_params(params)
lmd_w = params_tr.lmd_w
lmd_h = params_tr.lmd_h
n_rate = params_tr.n_rate
e_pos = _energy(vs_pos, hs_pos, w, z, b, c)
e_neg = _energy(vs_neg, hs_neg, w, z, b, c)
pw = _penalty_weight(w, lmd_w)
ph, const_ph = _penalty_hidden_act(vs_pos, w, z, c, lmd_h, n_rate)
consts = [vs_pos, hs_pos, vs_neg, hs_neg] + const_ph
return e_pos - e_neg + pw + ph, consts
|
1 2 3 4 5 6 7 8 9 | def _energy(vs, hs, w, z, b, c):
bsize = vs.shape[0]
s = T.exp(z)
s2 = 1.0 / s
e1 = T.mean(T.sum(0.5 * s2 * (vs - b)**2, axis=1))
e2 = T.mean(T.sum(c * hs, axis=1))
e3 = T.sum(T.dot((s2 * vs).T, hs) * w) / bsize
return e1 - e2 - e3
|
_get_cost()のe_posとe_negは式 (6) の二つの項に対応します. 両者は同じ式ですが, 期待値計算のためのサンプルが異なります. 第一項は経験分布と条件付き分布から得られるサンプルを用いるのに対して, 第二項はモデル確率分布 (PCD), またはそれを模した分布 (CD) から得られたサンプルを用います. また, ここではパラメータ と隠れ変数の活動に対するペナルティ項も加えられています. 本文書で示す実行結果ではこれらのペナルティ項は用いられていません (係数を0としています) .
このコスト関数のパラメータ微分を計算するとき, サンプリングデータのパラメータ依存性を断ち切る必要があります. これはコスト関数の式において期待値計算のサンプルに対応する変数 (vs_pos, vs_neg, hs_pos, hs_neg) は定数であると宣言することで行われます. これらの変数はリストconstsにまとめて呼び出し側に返され, 後でコスト関数のパラメータ微分を計算するときに用いられます.
パラメータ更新¶
パラメータ更新量 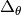 はパラメータ微分
はパラメータ微分 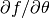 とモーメント項の重み付き和で計算します. ステップ
とモーメント項の重み付き和で計算します. ステップ 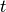 のパラメータを
のパラメータを 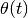 と表すと, モーメント項付きのパラメータ更新則は次のようになります:
と表すと, モーメント項付きのパラメータ更新則は次のようになります:

ここで 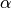 はモーメント項の減衰係数,
はモーメント項の減衰係数,  は学習係数を表します.
は学習係数を表します.
パラメータ更新量の更新とパラメータ自身の更新, それぞれに対応する共有変数更新式を返す関数が_get_updates_diff()と_get_updates_param()です. _get_updates_diff()のコードを以下に示します:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | def _get_updates_diff(t, cost, diffs, params, params_tr, consts):
# Model parameters
w, z, b, c = _get_params(params)
# Training parameters
alpha, eps0, decay = params_tr.alpha, params_tr.eps, params_tr.decay
eps = scipy.float32(eps0) * (scipy.float32(decay)**t)
# Parameter differences
dw, dz, db, dc = _get_diffs(diffs)
# Gradients
gw = T.grad(cost=cost, wrt=w, consider_constant=consts)
gz = T.grad(cost=cost, wrt=z, consider_constant=consts)
gb = T.grad(cost=cost, wrt=b, consider_constant=consts)
gc = T.grad(cost=cost, wrt=c, consider_constant=consts)
# # Parameter updates with momentum
update_dw = (dw, alpha * dw - eps * gw)
update_dz = (dz, alpha * dz - eps * gz)
update_db = (db, alpha * db - eps * gb)
update_dc = (dc, alpha * dc - eps * gc)
return [update_dw, update_dz, update_db, update_dc]
|
この関数の引数constsは_get_cost()の戻り値で, 前述したとおり, 微分の対象となる式の中で定数として扱う対象を表します. constsは微分を計算する関数theano.tensor.grad()の引数consider_constantに渡されます.
前述した通り, 共有変数更新式は, 更新される共有変数と更新後の式の組のタプルで表されます. 複数の共有変数をまとめて更新するため, 更新式を表すタプルのリストが呼び出し側に返されます.
_get_updates_param()もほぼ同様です:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | def _get_updates_param(diffs, params, params_tr):
# Model parameters
w, z, b, c = _get_params(params)
# Parameter differences
dw, dz, db, dc = _get_diffs(diffs)
# Tuples for update
update_w = (w, (w + dw))
update_z = (z, (z + dz))
update_b = (b, (b + db))
update_c = (c, (c + dc))
updates = []
if params_tr.is_update['w'] is True:
updates += [update_w]
if params_tr.is_update['z'] is True:
updates += [update_z]
if params_tr.is_update['b'] is True:
updates += [update_b]
if params_tr.is_update['c'] is True:
updates += [update_c]
return updates
|
params_tr.is_updateによって, パラメータを更新するかどうかを指定できるようにしています.
BBRBMの場合もほとんど同様に実装されます:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | def _get_updates_diff(t, cost, diffs, params, params_tr, consts):
# Model parameters
w, b, c = _get_params(params)
# Training parameters
alpha, eps0, decay = params_tr.alpha, params_tr.eps, params_tr.decay
eps = scipy.float32(eps0) * (scipy.float32(decay)**t)
# Parameter differences
dw, db, dc = _get_diffs(diffs)
# Gradients
gw = T.grad(cost=cost, wrt=w, consider_constant=consts)
gb = T.grad(cost=cost, wrt=b, consider_constant=consts)
gc = T.grad(cost=cost, wrt=c, consider_constant=consts)
# # Parameter updates with momentum
update_dw = (dw, alpha * dw - eps * gw)
update_db = (db, alpha * db - eps * gb)
update_dc = (dc, alpha * dc - eps * gc)
return [update_dw, update_db, update_dc]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | def _get_updates_param(diffs, params, params_tr):
# Model parameters
w, b, c = _get_params(params)
# Parameter differences
dw, db, dc = _get_diffs(diffs)
# Tuples for update
update_w = (w, (w + dw))
update_b = (b, (b + db))
update_c = (c, (c + dc))
updates = []
if params_tr.is_update['w'] is True:
updates += [update_w]
if params_tr.is_update['b'] is True:
updates += [update_b]
if params_tr.is_update['c'] is True:
updates += [update_c]
return updates
|
Theano関数の生成¶
生成されるTheano関数は次の四つです:
- update_diffs(): パラメータ更新量の更新を行います.
- update_params(): パラメータを更新します.
- init_particles(): Gibbsサンプリング連鎖の初期化を行います. PCDアルゴリズムで用いられます.
- get_info():
これらのTheano関数は, 関数_get_theano_functions()で生成されます. この関数自身は_init_theano()から上記で説明したTheanoオブジェクトやメタパラメータを引数として呼び出されます. 関数_get_theano_functions()はBBRBMとGBRBMで同じ実装を持ちます. コードは以下の通りです:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | def _get_theano_functions(
params, diffs, particles, algorithm, us, us_param, us_init_particles,
t, ixs, v0s, xs_tr, recon_err_tr, recon_err_vl, info):
if algorithm == 'cd':
update_diffs = function(
inputs=[t, ixs], outputs=[], updates=us,
givens={v0s: xs_tr[ixs]}, name='update_diffs')
elif algorithm == 'pcd':
update_diffs = function(
inputs=[t, ixs], outputs=[], updates=us,
givens={v0s: xs_tr[ixs]}, name='update_diffs')
else:
raise ValueError('Invalid value of algorithm: ' + str(algorithm))
update_params = function(
inputs=[], outputs=[], updates=us_param, name='update_params')
init_particles = function(
inputs=[ixs], outputs=[], updates=us_init_particles,
givens={v0s: xs_tr[ixs]}, name='init_particles')
get_info = function(
inputs=[], outputs=[recon_err_tr, recon_err_vl] + info,
name='get_info')
params.update(diffs)
return {'update_diffs' : update_diffs,
'update_params' : update_params,
'init_particles': init_particles,
'get_info' : get_info}, params, particles
|
四つのTheano関数は辞書に格納されて呼び出し側に返されます. さらに, 学習時に用いられる共有変数を持つ辞書paramsとparticlesも返されます. 辞書paramsに含まれるモデルパラメータは隠れ変数の予測や観測変数の復元で用いられますが, それ以外の共有変数は必ずしも必要ではありません.
呼び出し側の関数¶
以上で説明したクラスBBRBMおよびGBRBMを呼び出す関数はtest_rbms.pyに含まれます. BBRBMの訓練にはtest_rbms.train_bbrbm()を呼び出します (GBRBMにはtrain_gbrbm()が対応):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | def train_bbrbm(
t_start, t_end, n_components=512, alpha=0.0, eps=1e-2, algorithm='pcd',
lmd_w=0.0, lmd_h=0.0, batch_size=50, n_particles=50):
# Initialization of RBM
rbm = _init_bbrbm(
None, t_start, t_end, n_components=n_components, alpha=alpha, eps=eps,
algorithm=algorithm, lmd_w=lmd_w, lmd_h=lmd_h, batch_size=batch_size,
n_particles=n_particles)
# Get RBM filename
rbm_file = 'bbrbm-' + rbm.get_str() + '-t_' + str(t_end) + '.pklz'
# Training with parameters previouslly saved or new parameters
if 0 < t_start:
init_file = rbm.get_str() + '-t_' + str(t_start) + '.pklz'
data = load_pklz(init_file)
pca = data[0]
rbm = _init_bbrbm(data[1], t_start, t_end)
train_rbm(rbm, rbm_file, pca)
else:
train_rbm(rbm, rbm_file, 0)
|
L4-7で, 関数_init_bbrbm()を呼び出して初期化されたBBRBMオブジェクトを取得します. L11で結果を保存するファイル名を取得します. 学習結果のファイルに含まれるパラメータを初期値として学習を続ける場合の処理がL14-18です. L17とL20のpcaオブジェクトは前処理として観測変数を低次元空間に落とすPCAのパラメータを持ちます. 最後に関数train_rbm()を呼び出してRBMの訓練を行います:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | def train_rbm(rbm, rbm_file, pca0):
# Load data
xs_tr, xs_te = _load_mnist_data()
# Transform data to subspace
if type(pca0) == int:
pca = MyPCA(n_components=pca0)
pca = pca.fit(xs_tr)
else:
pca = pca0
_xs_tr = pca.transform(xs_tr)
_xs_te = pca.transform(xs_te)
if pca.pca is not None:
v = np.sum(pca.pca.explained_variance_ratio_)
print('%2.3f percent of variance explained' % (v * 100.0))
# Fit RBM
params_tr = rbm.params_tr
params_model = rbm.fit(_xs_tr, _xs_te).params_model
# Save estimated parameters
save_pklz(rbm_file, (pca, params_model, params_tr))
|
関数plot_bbrbm_weights() (GBRBMにはplot_gbrbm_weights()が対応) を呼び出す事で特徴量をプロットします:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | def plot_bbrbm_weights(
t_end, n_components=512, alpha=0.0, eps=1e-2, algorithm='pcd',
lmd_w=0.0, lmd_h=0.0, batch_size=50, n_particles=50):
# Get RBM filename
rbm = _init_bbrbm(
None, -1, t_end, n_components=n_components, alpha=alpha, eps=eps,
algorithm=algorithm, lmd_w=lmd_w, lmd_h=lmd_h, batch_size=batch_size,
n_particles=n_particles)
rbm_file = 'bbrbm-' + rbm.get_str() + '-t_' + str(t_end) + '.pklz'
# Extract weights from RBM parameters
def get_hidden_patterns(params_model, ixs):
return params_model['w'][:, ixs].T
# Plot
plot_rbm_weights(rbm_file, get_hidden_patterns, vminmax=(-0.5, 0.5))
|
実行結果¶
次のコマンドでBBRBMの訓練を実行します.
>>> import test_rbms
>>> test_rbms.train_bbrbm(0, 100)
0と100は訓練開始時と終了時のアルゴリズムの繰り返し回数を表します. 学習データとテストデータに対するRBMの復元誤差が減少する様子が分かると思います:
PCD-1 learning loop: 100 steps
Iteration 0, Error (train, test) = (0.730761 0.726575), time = 9.59s
Means (w, z, b, c) = (-1.87e-06, -4.59e+00, +6.36e-04, +3.32e-05)
Maxs (w, z, b, c) = (+6.68e-02, -4.45e+00, +3.41e-02, +3.57e-02)
Iteration 1, Error (train, test) = (0.664059 0.659440), time = 8.97s
Means (w, z, b, c) = (-6.86e-07, -4.58e+00, +6.40e-04, +3.12e-05)
Maxs (w, z, b, c) = (+7.73e-02, -4.38e+00, +3.41e-02, +3.56e-02)
Iteration 2, Error (train, test) = (0.622146 0.617181), time = 8.72s
Means (w, z, b, c) = (-5.96e-07, -4.57e+00, +6.44e-04, +2.88e-05)
Maxs (w, z, b, c) = (+8.23e-02, -4.32e+00, +3.41e-02, +3.55e-02)
Iteration 3, Error (train, test) = (0.591604 0.586418), time = 8.72s
Means (w, z, b, c) = (+5.92e-07, -4.56e+00, +6.49e-04, +2.69e-05)
Maxs (w, z, b, c) = (+8.85e-02, -4.27e+00, +3.41e-02, +3.55e-02)
100回のパラメータ更新後, カレントディレクトリにRBMの学習パラメータから構成される名前を持つファイルが作成されます. このファイルが持つRBMのパラメータを表示するコマンドは次の通りです:
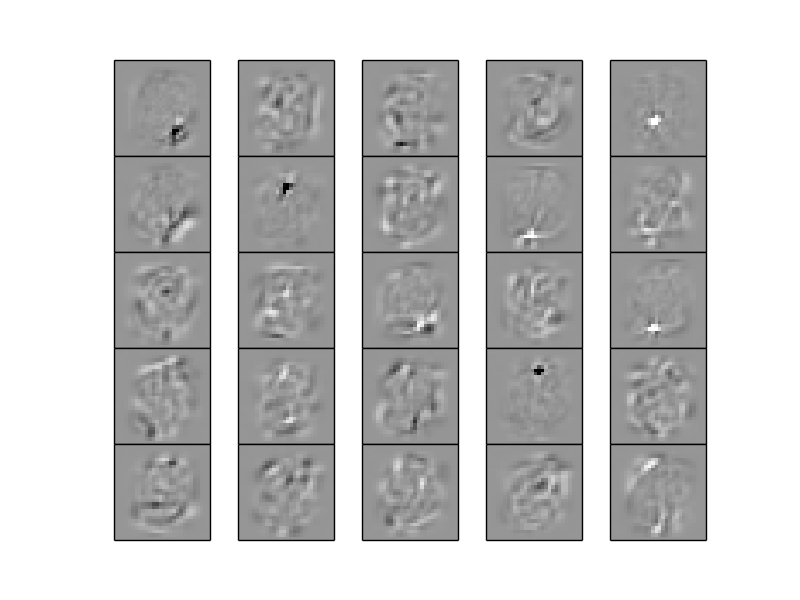
>>> test_rbms.plot_bbrbm_weights(100)
RBMのパラメータ に対応する次のような図が表示されます.

GBRBMについても同様に訓練とパラメータ表示を実行します:
>>> import test_rbms
>>> test_rbms.train_gbrbm(0, 100)
>>> test_rbms.plot_gbrbm_weights(100)
次のような図が表示されます:
まとめ¶
本文書ではTheanoの基本的な使い方を説明し, 応用としてRBMの実装例を示しました. Theanoの式の中で繰り返し計算を表現する関数scan()については触れませんでしたが, ここまでの説明でTheanoをある程度使いこなす事ができると思います.
GPUの利用や数式のグラフ表現は, 私の力不足のため触れる事ができませんでした. しかし, GPUを用いてCPUより数倍程度計算時間が短くなる場合がある事を確認しています. GPUに関する経験を重ね, いずれはその部分についても文書化したいと考えています. 数式のグラフ表現はデバッグや最適化に役立ちますが, 私は全く使いこなせていません. こちらについても今後調査したいと思います.
Theanoはまだ開発途中のライブラリであり, 仕様が変わる事も予想されますが, 式をシンボルで構築するという基本的な考え方は変わらないでしょう. この文書がTheanoの利用を検討される皆様のお役に立てば幸いです.
免責事項¶
本文書の情報については充分な注意を払っておりますが, その内容の正確性等に対して一切保障するものではありません. 本文書の利用で起きたいかなる結果について, 一切責任を負わないものとします。
参考文献¶
| [1] | Yoshua Bengio and Olivier Delalleau. Justifying and generalizing contrastive divergence. Neural Computation, 21(6):1601–1621, 2009. URL: http://dblp.uni-trier.de/db/journals/neco/neco21.html#BengioD09. |
| [2] | Miguel A. Carreira-Perpinan and Geoffrey E. Hinton. On contrastive divergence learning. 2005. |
| [3] | KyungHyun Cho, Alexander Ilin, and Tapani Raiko. Improved learning of gaussian-bernoulli restricted boltzmann machines. In Proceedings of the 21th International Conference on Artificial Neural Networks - Volume Part I, ICANN‘11, 10–17. Berlin, Heidelberg, 2011. Springer-Verlag. URL: http://dl.acm.org/citation.cfm?id=2029556.2029558. |
| [4] | (1, 2) Geoffrey E. Hinton. Training products of experts by minimizing contrastive divergence. Neural Comput., 14(8):1771–1800, August 2002. URL: http://dx.doi.org/10.1162/089976602760128018, doi:10.1162/089976602760128018. |
| [5] | Tijmen Tieleman. Training restricted boltzmann machines using approximations to the likelihood gradient. In William W. Cohen, Andrew McCallum, and Sam T. Roweis, editors, ICML, volume 307 of ACM International Conference Proceeding Series, 1064–1071. ACM, 2008. URL: http://dblp.uni-trier.de/db/conf/icml/icml2008.html#Tieleman08. |